Dimension “Completeness”
Loading Tree…
Definition
The degree to which expected data values are present.
Explanation
Completeness is a core dimension in most data quality concepts as the presence of data is a prerequisite for any analysis. (Weiskopf et al. 2013; Stausberg et al. 2015).
The key issue is: Which data values are available?
Completeness related indicators only cover whether or not data is present. They do not cover missing mechanisms, such as missing completely at random, missing at random or missing not at random (Schafer & Graham 2002). Therefore, the indicators are not designed to make direct inferences about bias but only about the count and proportion of available data and coded reasons for missing data.
The distinction into crude missingness and qualified missingness has been made to properly compute indicators under different preconditions of inadequate missing coding. This is further explained at the domain level.
Additionally, it is foreseen that completeness related indicators may be computed at different stages in a recruitment and data collection process (unit, longitudinal, segment, and item level). Different reasons may affect missing data values at each of these levels. This is further illustrated in the example below.
Example
The graph below depicts different levels at which nonresponse may occur. It shows a longitudinal study with two measurement waves and three examinations (interview, ECG examination, and somatometry) at each measurement point.
Subjects may either fail to take part:
in the entire examination (e.g. because they have moved)
a follow-up measurement wave (e.g. deceased)
one segment within a measurement wave - this equals an examination in this case such as somatometry (e.g. fulfilling an exclusion criterion)
selected data values may be missing within an examination.(e.g. due to technical failure of a device)
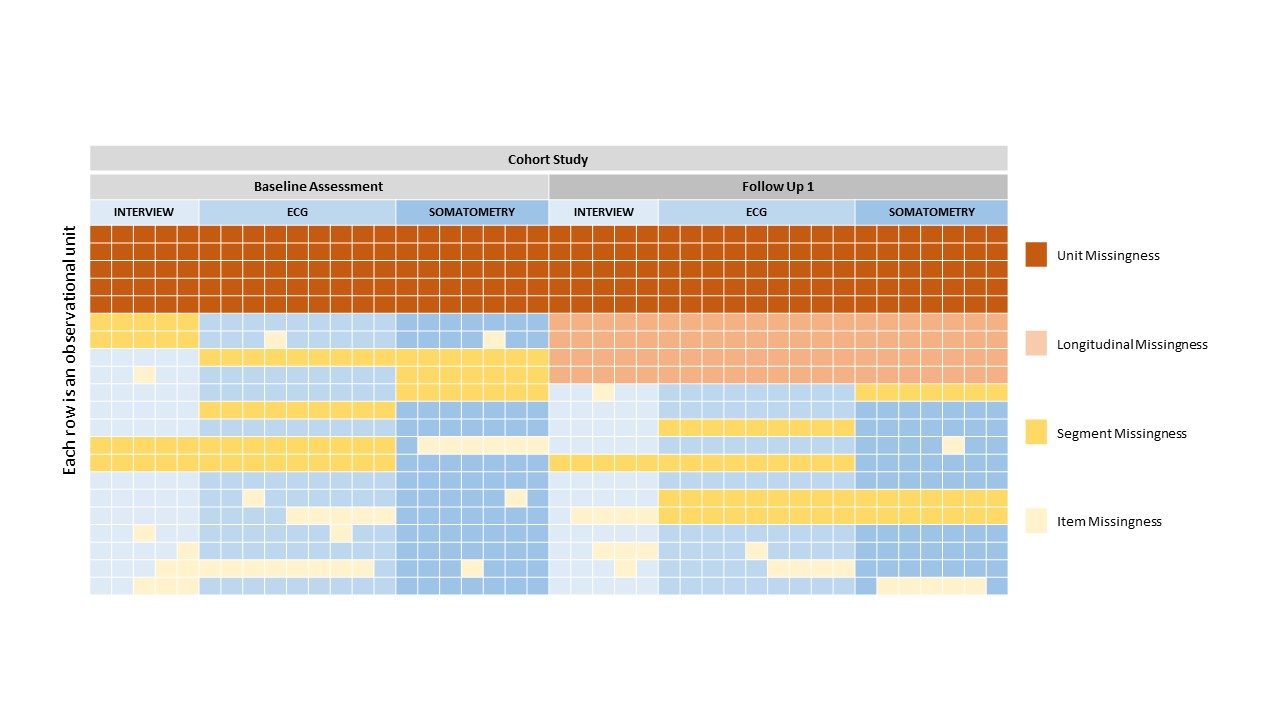
At each of these levels indicators within the domains crude missingness and qualified missingness may be computed.
Guidance
Before starting completeness related analyses it should be ensured that all relevant data structures (e.g. all variables and cases ) are technically represented in the data. Failure to do so may lead to misleading completeness results.
Completeness is targeted second in row after integrity but completeness should to be addressed before correctness, because only available data can be assessed for correctness and results from this step safeguard adequate computations of correctness related indicators.
Completeness related analyses lead to the following core results:
Knowledge about available study data and reasons at all levels of missing data is obtained.
As part of the assessment workflow all data values used for the qualification of observations as being missing values should be recoded to be technically treated as missing values in subsequent correctness relate analyses. This is important to avoid spurious results, because for example numerical missing codes are erroneously treated as extreme values.
Literature
Schafer JL, Graham JW. Missing data: our view of the state of the art. Psychol Methods. 2002;7(2):147-177.
Stausberg, J., D. Nasseh and M. Nonnemacher (2015). “Measuring data quality: A review of the literature between 2005 and 2013.” Stud Health Technol Inform 210: 712-716.
Weiskopf, N. G. and C. Weng (2013). “Methods and dimensions of electronic health record data quality assessment: enabling reuse for clinical research.” J Am Med Inform Assoc 20(1): 144-151.
